API vs. MCP.
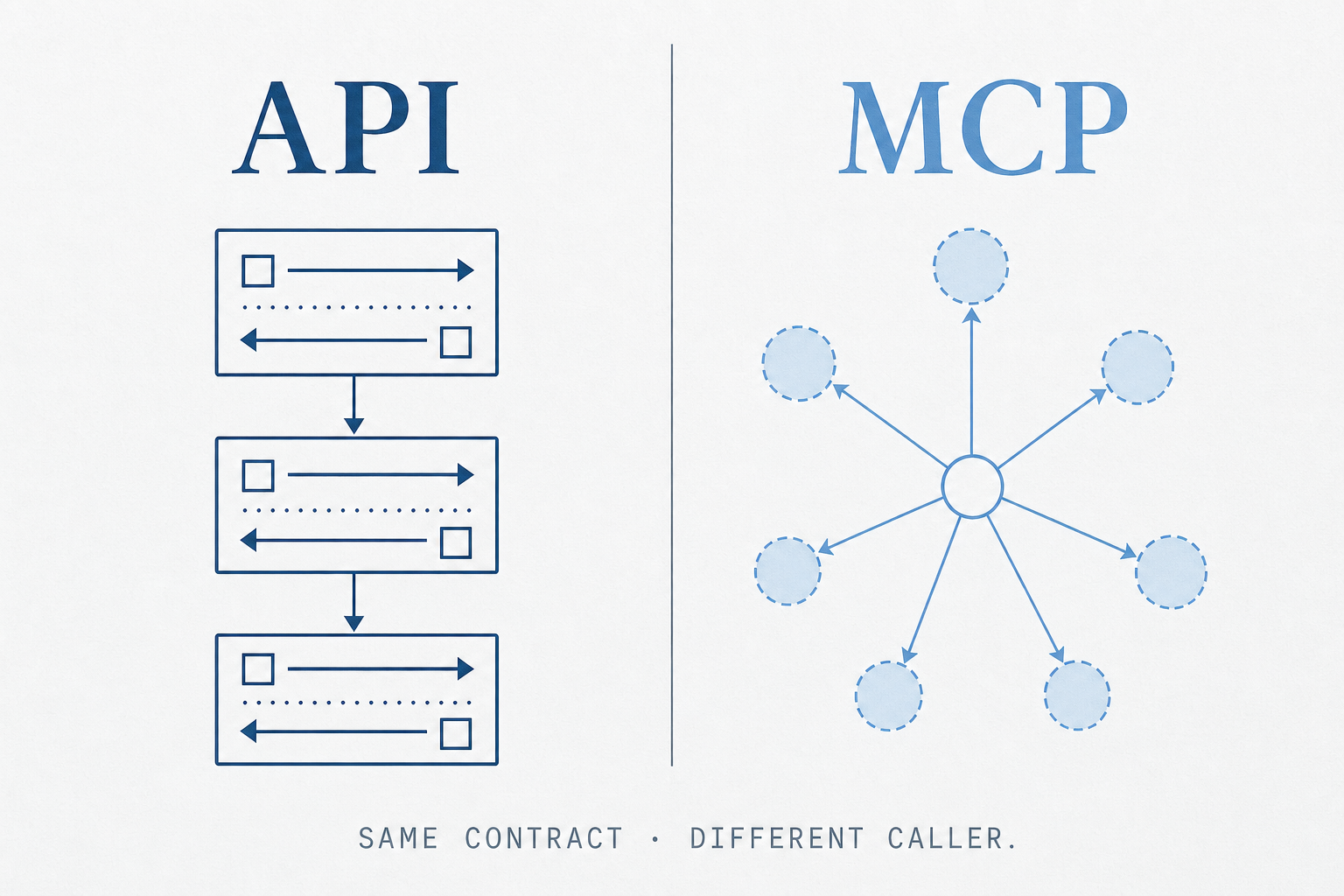
An API — REST, GraphQL, gRPC, whatever flavor — is a contract between two pieces of software the developer wires up at build time. The client knows the endpoints, the auth, the request shape, and the response shape because someone read the docs and coded it in. The
The shape of each
An API — REST, GraphQL, gRPC, whatever flavor — is a contract between two pieces of software the developer wires up at build time. The client knows the endpoints, the auth, the request shape, and the response shape because someone read the docs and coded it in. The contract is static; the discovery is human.
The Model Context Protocol is a thin standard that lets an LLM-powered client (Claude Desktop, Claude Code, Cursor, an agent runtime) connect to a server that advertises tools, resources, and prompts. The model reads the server's manifest at runtime, decides what to call, calls it, and feeds the result back into its context. The contract is still static under the hood — the server still exposes typed operations — but the discovery is dynamic and the caller is the model.
Put another way: an API is for the program you wrote. MCP is for the model you didn't.
The same task twice
Take a trivial task: "fetch the current weather for a city." Here is the API shape your application code uses today.
import os, httpx
def get_weather(city: str) -> dict:
resp = httpx.get(
"https://api.weather.example/v1/current",
params={"city": city},
headers={"Authorization": f"Bearer {os.environ['WEATHER_KEY']}"},
timeout=10,
)
resp.raise_for_status()
return resp.json()
print(get_weather("Austin"))
The developer chose the endpoint, the params, the auth header, the error handling. None of that is visible to a model; the model only sees whatever the surrounding application chooses to pass it.
Now the same capability exposed as an MCP server. The Python SDK uses decorators to register tools on a server; the model on the other end of the transport sees a typed tool called get_weather with a docstring and a schema, and can decide to call it.
import os, httpx
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("weather")
@mcp.tool()
def get_weather(city: str) -> dict:
"""Return the current weather for a city by name."""
resp = httpx.get(
"https://api.weather.example/v1/current",
params={"city": city},
headers={"Authorization": f"Bearer {os.environ['WEATHER_KEY']}"},
timeout=10,
)
resp.raise_for_status()
return resp.json()
if __name__ == "__main__":
mcp.run()
The function body is identical. The wrapping is what changes. The MCP layer turns a callable into something a model can find and invoke without any client-side code being written for it.
To wire that server into a client like Claude Desktop, you point a config at the executable.
{
"mcpServers": {
"weather": {
"command": "uv",
"args": ["run", "python", "/path/to/weather_server.py"],
"env": { "WEATHER_KEY": "sk-..." }
}
}
}
From that point on, any model session in that client can list and call get_weather without further code. That is the part that does not have an analog in the plain-API world.
What MCP is actually doing
Three things, mostly:
- Discovery. The client asks the server "what tools, resources, and prompts do you expose?" and gets a typed manifest back. The model gets to read it.
- Invocation. The model picks a tool, fills in arguments that match the schema, and the client forwards the call to the server. The result comes back as structured content the model can reason over.
- Transport portability. The same server can run over stdio (local subprocess), HTTP, or websockets. A tool you wrote once shows up in any MCP-aware client.
That last property is the under-discussed one. Once a capability is an MCP server, it works in Claude Desktop, in Claude Code, in Cursor, in custom agent runtimes — any host that speaks the protocol. You write the integration once instead of once per host.
When to reach for which
The decision is not "API or MCP." It is "who is the caller, and is the call path known at build time?"
- Reach for a plain API when a deterministic program is making the call, the call path is known in advance, latency or throughput matters, and you control both ends. Backend service to backend service. Mobile app to your own service. A scheduled job hitting a database.
- Reach for MCP when an LLM is the caller, the set of useful tools is open-ended, and you want the model to be able to discover capabilities without you re-shipping the agent. Internal "give Claude access to our knowledge base" deployments. Any tool you want to expose to multiple AI clients without writing N integrations.
- Use both when the MCP server is itself a thin shim over your existing API. This is the common case. The MCP server is twenty lines that wrap the SDK you already maintain. The auth, the rate limits, the data model — those still live in the API.
What MCP is not
A few things worth being precise about, because they get muddled:
- It is not a replacement for your API. The MCP server almost always calls an API behind the scenes. It is an adapter, not an alternative.
- It is not an agent framework. MCP defines how tools are exposed. It does not define the planning loop, memory, evaluation, or orchestration. Those still live in the agent runtime.
- It is not a security boundary on its own. An MCP server inherits the trust of whatever it can reach. Auth, scoping, and audit are still your job, and the right place to enforce them is at the API layer the server calls — not the server itself.
- It is not magic discoverability. Models still misuse poorly-named tools with vague descriptions. The schemas and docstrings you put on a tool are prompt engineering; treat them that way.
The mega context problem
The naive version of "expose your whole API as MCP" breaks at real scale, and the clearest articulation of why is Matt Carey's talk "MCP = Mega Context Problem". The numbers from Cloudflare make it concrete: roughly 2,600 endpoints, an OpenAPI spec of 2.3M tokens, which translates naively to ~1.1M tokens of MCP tool definitions before any work begins. No frontier model's context window survives that.
Cloudflare's first move was to split the surface across product-aligned servers — they ended up shipping 16 of them. That kept individual sessions tractable, but pushed the burden onto users (pick the right server) and forfeited the original promise of "every API a tool for agents." Six tools sitting on top of thirty endpoints isn't coverage; it's a sample.
Carey's framing is that MCP isn't the problem — dumping every tool into context is. The fix is progressive discovery, and three patterns are live:
- CLI as a tool surface. The agent gets shell access and introspects via
--help. Popular with Claude Code; works; needs a shell, which not every host hands out. - Tool search. One search tool that the model calls with the user's intent, which loads ~6–8 relevant tools into context on demand. The rest of the catalog stays unloaded. This is what Claude Code does internally and what makes MCP viable at enterprise-API scale.
- Code mode. The model is given typed bindings (a TypeScript SDK generated from the OpenAPI spec) and writes code against them, instead of issuing N individual tool calls. Code is a compact plan: one
codetool with many degrees of freedom in place of a tool-per-endpoint catalog. Cloudflare's "Code Mode" post claims an entire API in a thousand tokens.
Code mode was a non-starter until very recently because executing untrusted, model-generated code used to be a CVE. The unlock is sandboxes that are programmable at the boundary — V8 isolates (Workers / WorkerD), Deno with explicit permission flags, Pyodide-based interpreters like Pydantic's. You hand the model a runtime where process.env is empty, network access is denied by default, and you flip booleans to grant exactly the capabilities it needs.
A consequence worth flagging if you ship an API: agents driving sandboxed for-loops will hammer it. Good rate limiting stops being a nice-to-have and becomes the boundary that protects you from ten parallel sandboxes generating code against the same endpoints in a tight loop.
Carey's bet for the next year is that MCP becomes a one-line flag in mainstream frameworks — mcp: true on a Next.js app exposing existing routes — once the SDK is small enough to ship by default. If that's right, the question stops being "should we build an MCP server" and becomes "is the flag flipped on the framework we already use."
MCP at enterprise scale
The context-window problem is an engineering constraint. The governance problem is an organizational one. Karan Sampath (Anthropic forward-deployed engineer) put it plainly in a talk titled "Bringing MCPs to the Enterprise": individual teams can now build MCP servers quickly — the bottleneck is that they can't get them deployed, and security teams are too overwhelmed to vet each one. The result is that most enterprises are stuck with a handful of tools when they need hundreds.
The three blockers he identifies form what he calls a three-headed hydra:
- Observability. Who is calling which tools, how often, and which tool definitions are underperforming? Completely opaque today with no standard MCP-layer answer.
- Access control. Different teams should see different subsets of tools; different roles within a team should have read vs. write access to the same server. The protocol supports this in principle but there's no standard mechanism for enforcing it.
- Security. How do you verify a new server isn't a data-exfiltration vector? How do you let untrusted remote clients reach private internal data without opening a hole? Questions the API world solved decades ago with auth layers that MCP has yet to formalize.
Sampath's proposed fix is the MCP gateway: a single middleware layer that sits between all of your MCP servers and all of your MCP clients. Every client sees only the gateway; the gateway routes to whichever servers the client is authorized to reach. The servers treat the gateway as their sole trusted endpoint.
The key idea — the one he explicitly flags as the most important slide — is root of trust through a single blessed platform. Security teams can't vet forty MCP servers in parallel, but they can vet one gateway. Once the gateway is vetted, any new server that deploys behind it inherits the access control, observability, and credential management without a new security review. That's what makes decentralized development tractable: the governance surface stays fixed even as the tool catalog grows.
A complete gateway contains roughly six components: an auth layer (pluggable into your existing IDP), role-based access control, a proxy that clients talk to instead of servers directly, a secure tunnel for the internal leg, an internal sub-registry of available servers, and a CLI that makes registering a new server a one-command operation. That last piece matters: it means the legal team's contract-review MCP can be written and deployed by the legal team, without them touching the five governance concerns.
The follow-on benefits Sampath walks through:
- Surface portability. claude.ai, Claude Code, Claude Code in Workspaces — all can point at the same gateway. New Anthropic surfaces get your full tool catalog on day one.
- Faster iteration. A team can update their MCP without a per-change security review, because the gateway's invariants already constrain what's possible.
- Standard primitives. The gateway can encode company-wide operating procedures — the tools that must exist, the patterns that are forbidden — so every new server inherits them.
- Pluggable credentials. One server can accept company-wide tokens, team tokens, and service accounts without any per-server credential plumbing.
- Scalability. Routing and load-balancing across hundreds of servers is a gateway problem, not a problem you solve forty times.
The longer arc he's pointing at: separating the agent harness (the planning loop, the orchestration) from the data layer (your MCP servers and the APIs behind them). Today those are entangled — your agent is often written assuming specific tool names and behaviors. A gateway makes the data layer stable enough that you can swap the agent harness (cloud managed agents vs. self-hosted Claude agent SDK vs. something else entirely) without re-wiring your tools. The gateway is the invariant; the agent becomes a plug-in.
The mental model I use
APIs are for programs that already know what they want to do. MCP is for models that need to figure out what they can do. The first is a contract; the second is a catalog.
If you are building a service, ship an API. If you want a model to use that service without you writing the glue every time, wrap it in an MCP server. The two layers compose; the question of which one to write first is almost always "API first, MCP second" — because the MCP server is a leaf that depends on the API existing, not the other way around.
Sources
- Matt Carey, "MCP = Mega Context Problem" (Cloudflare).
- Karan Sampath, "Bringing MCPs to the Enterprise" (Anthropic).